[AWS] Data Analysis
Athena

- 서버리스 쿼리 서비스이며 QuickSight와 조합하여 대시보드 만드는 구조로 자주 쓰임
- 성능 향상도 가능하며 열기반과 압축 데이터를 스캔하면 비용 절감에 유리
- 열기반은 컬럼을 의미하는데 보통 Apache Parquet과 ORC 방식이 추천됨 (둘다 데이터 포맷임)
- 파티션으로 분할해도 성능 향상에 도움이 됨
- 큰 파일을 쓰는 게 작은 파일 여러개 보다 도움이 됨

- 연합 쿼리를 사용해서 여러 데이터를 조합할 수도 있음
Redshift

- 데이터베이스이자 분석엔진 (postgreSQL)
- 재밌는 건, OLTP 용도로 쓰이지 않고 OLAP 용도로 쓰이는 거임
- 데이터를 쿼리하기 전에 전부를 불러오기 때문에 아테나 보다 성능이 좋음
- 단일, 다중 AZ 지원

- 클러스터에 데이터를 집어넣는 방법은 총 3가지가 있음
- Redshift Spectrum을 쓰면 데이터 로드 없이 분석이 가능
OpenSearch Service

- 라이센스 때문에 이름 바뀜
- 검색 엔진 개선에 많이 쓰이고 서버리스 방식과 클러스터 관리 방식으로 나뉨
- 네이티브 쿼리를 지원하지 않아서 플러그인 써야함
EMR
- Elastic MapReduce
- 하둡 클러스터들을 생성해서 (빅데이터 처리용) 분석하고 처리
- 스파크나 HBase 같은 거 프로비저닝 자동으로 해줌
- 온디맨드, 예약, 스팟 인스턴스 3가지 지원함
QuickSight


- 상호작용 가능한 대시보드 만들어주는 서비스
- 데이터를 Import 할 때, 내부적으로 인메모리 캐시인 SPICE 엔진을 사용함
Glue

- extract, transform, and load (ETL) service
- 새 ETL 작업을 실행할 때 이전 데이터의 재처리를 방지
Lake Formation
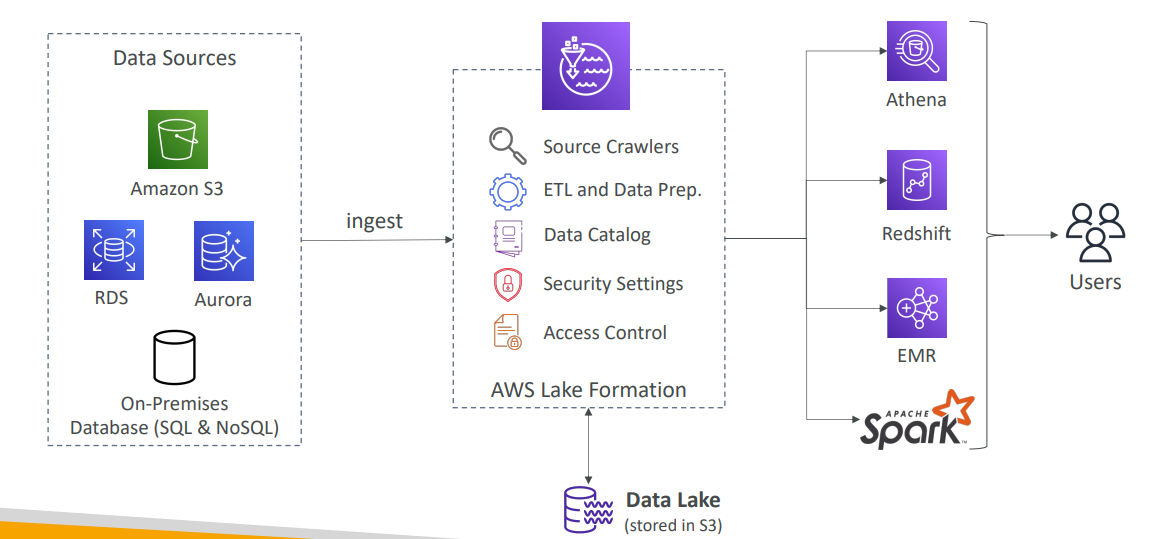
- 데이터 레이크는 데이터 분석을 위한 중앙 장소를 의미
- 수집, 복제, 학습 같은 거 다 해주는 완전 서비스형
MSK

- Managed Streaming for Apache Kafka
파이프라인 예시

솔루션 아키텍트로서 Redshift 클러스터에 대한 재해 복구 계획을 수립하는 업무를 맡았습니다. 어떤 작업을 해야 합니까?
- 다중 AZ를 활성화한다.
- 자동 스냅샷을 활성화한 다음, Redshift 클러스터가 스냅샷을 다른 AWS 리전으로 자동 복사하도록 설정한다.
- 스냅샷을 만들고 Redshift 글로벌 클러스터로 복원한다.
한 회사가 AWS를 사용해 자사의 공용 웹 사이트와 내부 애플리케이션을 호스팅하고 있습니다. 이들 웹 사이트와 애플리케이션에서는 수많은 로그 및 트레이스가 생성됩니다. 로그를 중앙 집중식으로 저장하여 실시간으로 검색하고 분석해 오류와 악의적인 시도를 감지할 수 있도록 만들어야 합니다. 로그를 효율적으로 저장하고 분석하는 데 도움이 되는 AWS 서비스는 무엇입니까?
- Amazon S3
- Amazon OpenSearch service
- Amazon ElastiCache
- Amazon QLDB